
Episode 05 : Web !
Episode 05 : Le Web

PROLOGUE
Le lien entre le web et internet est le même qu’entre l’autoroute et une voiture. Le web est en grande partie le contenu qui circule sur le réseau internet, comme les sites, les réseaux sociaux, etc. C’est l’un des éléments principaux qui utilisent internet, même si ce n’est pas le seul. C’est une voiture, mais il y a aussi des motos (comme l’e-mail) ou des camions (comme la vod [Netflix, Amazon Prime...] ). Maintenant que l'on a vu comment les informations sont transmises avec précision où que l'on soit sur terre, on va désormais voir en quoi ces innovations techniques ont permis une REVOLUTION de notre société, avec des modifications profondes de nos comportements, à la fois individuels et collectifs, de notre rapport au savoir et des enjeux politiques que cela occasionne !

Au début, il y avait des ordinateurs. Les gens les utilisaient pour faire des calculs et stocker des informations, mais ils ne pouvaient pas les partager facilement avec d'autres personnes. Puis, un homme nommé Tim Berners-Lee a eu une idée brillante. Il a inventé quelque chose appelé le World Wide Web (Web mondial). C'était comme une toile géante où les informations pouvaient être liées les unes aux autres. La grande force du web, c’est que le contenu affiché peut être de la vidéo, de la photo, de la musique et du texte. C’est la solution la plus polyvalente pour faire passer de l’information aujourd’hui. L'idée géniale, qui fonde le web, c'est le lien hypertexte.
Les liens hypertextes
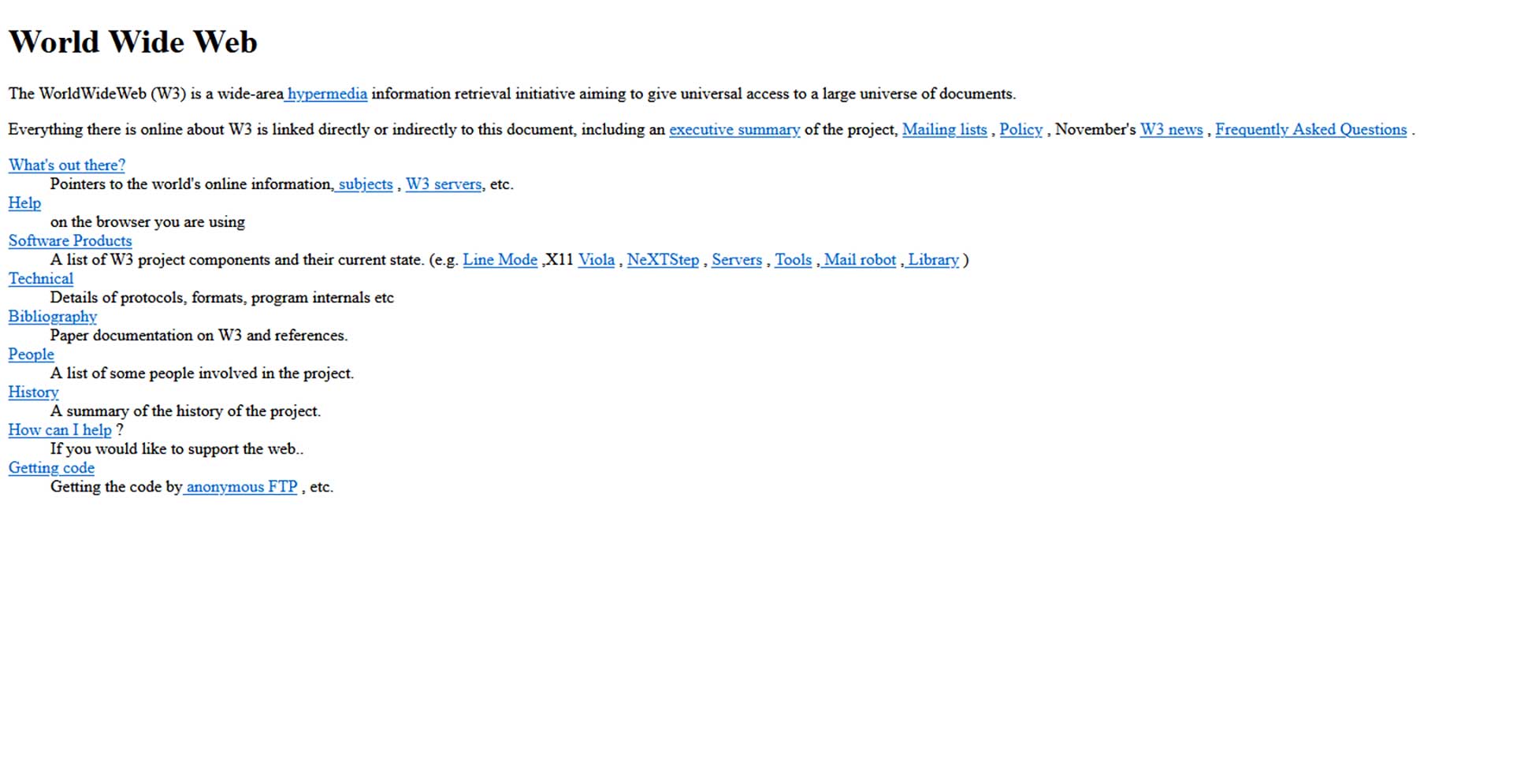
Voilà l'image du premier site internet de l'histoire. A l'époque, il n'y avait pas d'image, pas de son ,pas de vidéo juste... du texte et des liens hypertextes (les mots en bleu...), et c'est cela qui va changer le monde !
Le site est toujours en ligne ! Il est consultable en cliquant sur le bouton suivant :
Le principe du lien hypertexte est révolutionnaire car il permet de relier des informations entre elles de manière non linéaire sur le web. À l'aide de liens hypertextes, un simple clic permet de passer d'une page à une autre, d'un sujet à un autre, en naviguant librement à travers un océan d'informations. Cette structure flexible offre une expérience utilisateur interactive et dynamique, permettant aux personnes d'accéder rapidement à une multitude de contenus. Le lien hypertexte facilite le partage de connaissances, l'exploration et la découverte, contribuant ainsi à la démocratisation de l'information et à la connectivité mondiale. Cliquer sur un mot, et aller directement à un contenu qui le concerne, est devenu tellement utilisé qu'on se demande même comment on a pu vivre sans. L'ensemble des réseaux sociaux sont fondés sur ce principe : je vois un extrait de vidéo, je clique dessus, et j'accède immédiatement à son contenu ! Dans le monde d'avant, pour avoir accès à un texte, une musique ou une vidéo, il fallait aller en bibliothèque, ou médiathèque, demander à voir un texte, un CD ou une cassette VHS et les regarder sur place, ou les emprunter pour la voir chez soi sur un magnétoscope ! Aujourd'hui, tout est accessible, immédiatement et presque sans effort !
le WEB, comment ça marche ?
Les liens URL
Tim Berners-Lee a l'idée de remplacer les adresses IP par des liens URL bien plus faciles à mémoriser. Chaque site à donc une adresse car elle est stockée sur un ordinateur spécial appelé un serveur. Ainsi, on ne va plus chercher une adresse avec un numéro IP, mais par un chemin lié à un nom comme : http://www.petit-prof-de-snt.com.
http:// Cela veut dire Hyper Text Transfert Protocole.
C'est l'ensemble des règles qui vont associer un nom de domaine à une adresse IP.
www.petit-prof-de-snt.com C'est le nom de domaine.
Un nom de domaine est nom de propriété unique au monde. Un peu comme une adresse mail, il ne doit pas y en avoir deux identiques car cela créerai des bugs! On ne l'achète pas, on le loue à un organisme internationnal dont la fonction est de veiller à ce que personne n'utilise des noms de domaines identiques ! Pour information, je loue le nom de domaine petit-prof-de-snt.com 8 euros par an, ce qui n'est pas grand chose, cet argent sert à financer cette institution indispensable au bon fonctionnement du web.
les serveurs
Avoir une adresse url ne suffit pas, il faut aussi avoir un petit territoire où le stocker. La solution la plus commune est de louer un morceau de serveur où l'on va copier les pages du site internet. Ces pages seront alors copiées à leur tour et envoyées vers les utilisateurs qui veulent les consulter. On ne voyage pas sur le web, en fait, c'est le monde qui est transféré par copie sur votre ordinateur ou téléphone.
Comme personne ne comprenait rien à l'informatique, Tim Berners-Lee a appelé ces ordinateurs des serveurs car ils sont chargés de récupérer les commandes de page web des "clients / internautes" et de leur apporter ces pages le plus vite possible.
les clients/ les navigateurs
Pour voir le web, des entreprises ont créé des programmes spéciaux appelés navigateurs web, comme Internet Explorer, Firefox et Google Chrome. Avec ces navigateurs, les gens pouvaient explorer le Web en cliquant sur des liens hypertextes. Enfin, les gens ont commencé à se connecter au Web à partir de différents appareils, comme des ordinateurs, des téléphones et des tablettes.
Aujourd'hui, le Web est partout autour de nous, et nous l'utilisons pour tout, de la recherche d'informations à la communication avec des amis à travers le monde. Ici, on va voir une différence majeure entre l'Europe et les Etats-Unis! Tim Berners-Lee pense que son invention peut révolutionner le monde et il décide de la rendre GRATUITE !
TOUT LE MONDE PEUT APPRENDRE, COMPRENDRE ET UTILISER SON INVENTION GRATUITEMENT.

Le web est créé en 1989, c'est-à-dire que l'inventeur a mis au point le système de gestion de base du Web, le protocole http, le système des serveurs et des liens URL et en 1993, tout cela peut être utilisé gratuitement ! Aujourd'hui, les 5 entreprises numériques les plus riches du monde, les GAFAM (Google, Apple, Facebook, Amazon, Microsoft) gagnent énormément d'argent en utilisant une ressource qui leur a été offerte gratuitement, ne l'oublions pas. A ma toute petite échelle, le fait que je vous donne accès à ce site gratuitement est un hommage que je fais à Tim Berners-Lee et à tous ceux qui donnent de leur temps gratuitement afin d'aider la société, chacun de leur côté ! <3
Tim Berners-Lee
C'est ainsi que le Web est devenu un outil essentiel dans nos vies car la révolution prédite a effectivement eu lieu : En 1995, le World Wide Web était encore à ses débuts, et le nombre de sites web était extrêmement limité. On estime qu'il y avait seulement quelques centaines de sites web à cette époque, principalement des sites académiques et de recherche. 2000 : Au tournant du millénaire, le nombre de sites web avait considérablement augmenté. On estime qu'il y avait environ 17 millions de sites web actifs à la fin de l'année 2000. L'expansion d'Internet et l'avènement du commerce en ligne ont contribué à cette croissance. En 2010, le nombre de sites web avait explosé. On estime qu'il y avait environ 255 millions de sites web actifs à travers le monde. Cette décennie a vu une augmentation massive des sites web, des blogs personnels aux sites d'entreprises en passant par les réseaux sociaux. En 2020, le nombre de sites web actifs avait encore augmenté. Les estimations varient, mais on estime qu'il y avait plus d'un milliard de sites web actifs à travers le monde à la fin de l'année 2020. Cette croissance continue est due à la prolifération des sites web dans tous les domaines, y compris le commerce électronique, les médias sociaux, les blogs, les sites d'information, etc.

le Web 1.0
Le Web 1.0 était la première phase du World Wide Web. Il était principalement statique, ce qui signifie que les utilisateurs ne pouvaient que consulter le contenu en ligne sans vraiment interagir avec lui. Les sites web étaient principalement des pages HTML simples avec du texte et des images. Il n'y avait pas beaucoup d'interaction entre les utilisateurs et le contenu, et la mise à jour des informations sur les sites web était souvent difficile.
le Web 2.0
Le Web 2.0 est venu après le Web 1.0 et a introduit une approche plus interactive et participative du web. Les utilisateurs pouvaient contribuer au contenu des sites web, créer des profils, interagir avec d'autres utilisateurs et partager du contenu. Les sites web étaient plus dynamiques et permettaient aux utilisateurs de participer activement en commentant, en partageant et en créant du contenu. Les exemples incluent les réseaux sociaux comme Facebook, Insta ou TikTok, les plateformes de partage de vidéos comme YouTube, Netflix ou PrimeVidéo et les blogs.
le Web 3.0
Le Web 3.0 est une évolution du Web 2.0 qui vise à rendre le web plus intelligent et plus personnalisé. Il met l'accent sur l'utilisation de technologies telles que l'intelligence artificielle, le traitement du langage naturel et la blockchain pour offrir des expériences plus personnalisées et sécurisées aux utilisateurs. Le Web 3.0 vise également à rendre les données plus interopérables entre les différents sites et services en ligne, permettant aux utilisateurs de mieux contrôler leurs informations personnelles et leur vie numérique.

HTML et CSS
HTML (HyperText Markup Language) et CSS (Cascading Style Sheets) sont deux langages distincts utilisés pour concevoir et styliser des pages web. Voici pourquoi ils sont utilisés ensemble en quelques points : Structure et contenu : Le langage HTML est utilisé pour définir la structure et le contenu d'une page web. Il permet de créer des éléments tels que des paragraphes, des titres, des listes, des images, etc., qui constituent le squelette de la page. CSS, quant à lui, est utilisé pour définir la présentation et le style de ces éléments HTML. Il permet de contrôler des aspects visuels tels que la couleur, la police, la taille, la disposition et les effets visuels des éléments HTML. On trouve aujourd'hui des écrans de toutes formes et de toutes tailles. C'est en 2016 que pour la première fois, il y a eu plus de consultations de sites internet par les téléphones portables que par les ordinateurs. Ces différentes tailles et résolutions ont poussé le web à s'adapter. En effet, l'ordinateur a un écran plutôt horizontal alors que le téléphone est utilisé majoritairement avec un écran vertical. Le CSS permet ainsi de modifier l'apparence du site à tous les types d'écrans, quelles que soient leur nature et leur résolution, sans changer leur structure, assumée par le html !
Le langage HTML
Le langage HTML n'est pas un langage de programmation car il ne permet pas de faire des calculs comme avec Python par exemple. Il est ce qu'on appelle un langage de balisage car tout le site est hierarchisé grâce à la présence de balises ouvertes puis fermées. Ces balises ont toujours le même fonctionnement : On commence une balise ouverte avec le signe < puis une instruction puis le signe >. On ferme la balise avec le signe . Par exemple, pour écrire un paragraphe de texte, il faut donner les instructions suivantes : < p > voila le texte < /p > Notez que c'est la barre "/"" qui distingue une commande de fin d'une instruction du début.
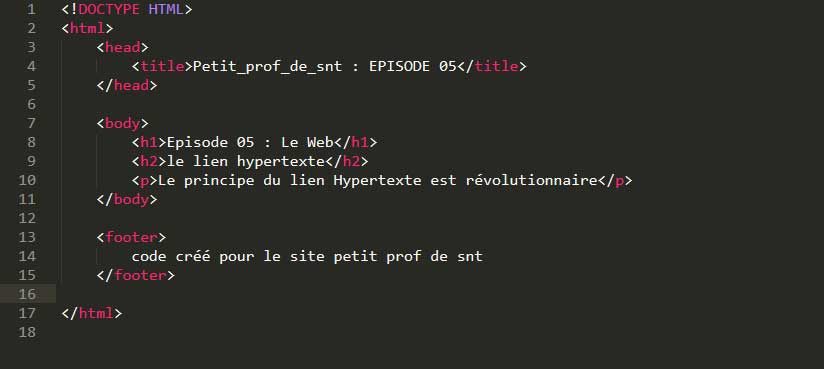
Ainsi, ce n'est pas comme dans un logiciel comme "Word", il y a une différence entre ce que l'on écrit et ce que le navigateur affiche ! Ainsi losqu'on écrit le programme suivant :
Le navigateur affiche cela :

C'est pour cela que l'on parle de langage de balisage. On voit bien comment le site se structure en fonction de la taille des titres et de leur succession dans la page. La première balise d'un site internet est toujours : < !DOCTYPE HTML . Un site internet est toujours découpé en 3 parties : la tête (head), le corps (body), et les pieds (footer). On voit comment chaque partie commence et se termine par la même instruction : < head > pour commencer et < /head > pour terminer Chaque partie a ses spécificités : < Head > _ _ _ _ _ < /head > Cette partie concerne l'organisation de la page dans sa structure. C'est là que l'on va donner les instructions pour pouvoir dire quel style CSS va s'appliquer sur la page ou qu'on va donner le titre de la page tel qu'il va s'afficher dans le navigateur et non pas dans le contenu textuel de la page. Ainsi: < title > Petit_prof_de_snt : EPISODE 05 < /title > va s'afficher de cette manière DANS L'ONGLET du navigateur :

< Body > _ _ _ _ _ < /Body > C'est le corps du site. Les différents éléments de la page, le titre, les images ou les vidéos, s'afficheront ici. < H1 > _ _ _ < /H1 > : C'est la commande de titre. Le texte s'affiche en gros et en gras pour qu'il soit bien visible ! < p > _ _ _ < /p > : C'est la commande de paragraphe. Le texte s'affiche en petit.
< Footer > _ _ _ _ _ < /Footer > C'est le pied du site, c'est là que va s'afficher les différents éléments liés aux copyrights du site.
Au début, il n'y avait pas d'image, alors pour égayer un peu les pages, les développeurs se sont amusés à inventer des textes un peu spéciaux, se sont les ancêtres des émojis !
Le langage CSS
C'est un langage qui ressemble un peu à une liste de courses ! Chaque élément employé dans le langage html va être réutilisé avec des spécifications de taille, de couleur, de placement, etc... Il va permettre au site de s'afficher de différntes manières possibles en fonction de la taille des écrans! Ce genre de site modulable s'appellent : Un site RESPONSIVE !

Etude de cas: GOOGLE
1997 : Moteur de recherche Larry Page et Sergey Brin ont fondé Google en 1998, mais le moteur de recherche lui-même a été lancé officiellement en septembre 1997, bien que son développement ait commencé plus tôt dans le garage de Susan Wojcicki à Menlo Park, en Californie. Son coup de génie : faire un moteur de recherche basé sur l'I.A. qui référence avec une très grande précision les sites web actifs sur le web. On n'a plus besoin de connaitre le nom d'un site, ou son adresse URL, il suffit de taper son nom dans le moteur de recherche et Google vous y emmène via un lien Hypertexte. C'est gratuit et très pratique ! Mais alors comment fait Google pour gagner des milliards de dollars chaque année avec des applications gratuites ?
Si c'est gratuit, c'est TOI le produit !
Google enregistre les différentes recherches de l'utilisateur : grâce à cela, l'entreprise connait plein de choses sur vos centres d'interêts, vos peurs, vos rêves, vos espoirs, etc.... et revend tout cela à des entreprises qui vont vous CIBLER avec des publicités qui vous seront envoyés en fonction de vos centres d'intérêt ! ça marchait bien, mais Google a eu une autre idée afin de récupérer encore plus de données : 2004 / Gmail a été lancé en version bêta le 1er avril 2004 et est devenu accessible au public le 7 février 2007. Il a été développé par Paul Buchheit, un ingénieur de Google. Très pratique, bien pensé, GRATUIT, offrant plusieurs giga d'espace disque, c'est une super application. AU PASSAGE, GOOGLE SE RESERVE LE DROIT DE LIRE TOUS VOS MAILS ! Ils ont aussi accès à tous vos contacts, documents, etc... Depuis 2012, ils ont promis qu'ils ne liraient plus les mails à des fins politiques ! Il n'ont jamais dit à des fins commerciales ! Ca marchait bien, mais google a eu une autre idée afin de récupérer encore plus de données : 2005 / Google Maps a été lancé le 8 février 2005. Il a été créé grâce à l'acquisition de la société australienne Where 2 Technologies par Google en 2004. Google Maps offre des cartes détaillées, des images satellites, des vues panoramiques et des informations sur les lieux du monde entier. AU PASSAGE, GOOGLE SE RESERVE LE DROIT DE CONNAITRE TOUS VOS DEPLACEMENTS ET DE TOUT ENREGISTRER, minutes après minutes, où vous êtes, à chaque instant ! Toutes ces informations sont enregistrées et stockées pour une durée illimitée ! Ca marchait bien, mais google a eu une autre idée afin de récupérer encore plus de données : 2008 /Google Chrome a été annoncé pour la première fois en septembre 2008 et a été officiellement lancé en version stable le 11 décembre 2008. Il a été développé pour offrir une navigation plus rapide, plus simple et plus sécurisée sur le web. Par sécurisée, il faut entendre que Google ne partage plus les données récupérées avec les autres mais les garde pour lui. Cela lui permet également de surveiller tout ce que vous faites sur Facebook. Depuis le développement des applications dédiées, c'est un peu moins utile, mais bon, on va le garder, on ne sait jamais !
La monétisation du WEB : les DATAS
L'histoire des données personnelles et de leur vente est une question complexe qui concerne la façon dont nos informations personnelles sont collectées, stockées et utilisées par les entreprises afin de cibler les utilisateurs à qui elles veulent vendre leur produits !
De nombreuses entreprises collectent des données personnelles à partir de diverses sources, y compris les sites web que vous visitez, les applications que vous utilisez, les réseaux sociaux, les achats en ligne, les transactions bancaires, etc. Ces données peuvent inclure des informations telles que votre nom, votre adresse, votre adresse e-mail, vos préférences, vos habitudes d'achat, votre historique de navigation, etc. Certaines entreprises vendent ces données à d'autres entreprises, annonceurs ou partenaires commerciaux. Ces données peuvent être utilisées pour cibler des publicités, développer de nouveaux produits, mener des études de marché, évaluer la concurrence, etc.
Moi, je m'en moque, j'ai rien à cacher !
La collecte de données personnelles peut influencer vos contrats d'assurance de plusieurs manières : Les compagnies d'assurance utilisent souvent des données personnelles pour évaluer le risque que vous représentez en tant qu'assuré. Par exemple, votre historique de conduite, votre âge, votre lieu de résidence et d'autres informations peuvent être utilisés pour déterminer le montant de votre prime d'assurance. Si les données collectées suggèrent que vous présentez un risque plus élevé, vous pourriez être confronté à des primes plus élevées. Vos données personnelles peuvent influencer les conditions de prêts bancaires de plusieurs manières : Les banques utilisent vos données personnelles pour évaluer votre solvabilité et déterminer votre capacité à rembourser un prêt. Des informations telles que votre historique de crédit, vos revenus, votre emploi, vos dettes existantes et d'autres informations financières peuvent être prises en compte pour évaluer le risque que vous représentez en tant qu'emprunteur. Les banques peuvent ajuster le montant du prêt en fonction de votre situation financière et de vos antécédents de crédit. Si vous avez un bon historique de crédit et des revenus stables, vous pourriez être admissible à un prêt plus important. À l'inverse, si vous présentez un risque plus élevé, la banque pourrait limiter le montant du prêt ou exiger des garanties supplémentaires. En conclusion : Vos données personnelles sont utilisées par les banques et les assurances, entre autres, pour évaluer votre admissibilité à un prêt, déterminer les conditions du prêt et établir les termes de remboursement. Vos données personnelles ont une grande importance et certains payent très cher pour les récupérer. On estime à 80 000 000 000 d'euros (80 milliards) le marché des données personnelles pour 2024.
Le Scandale Cambridge Analytica
Le scandale Cambridge analytica est sorti en 2017 aux Etats Unis. Cambridge Analytica est une société financée par la Russie. Elle a récupéré, via Facebook, des données de millions d'utilisateurs américains, et elle a utilisé ces données afin de cibler les électeurs dits "indécis" afin qu'ils aillent voter pour le candidat le plus favorable à la Russie en utilisant des tactiques telles que la désinformation, la propagation de fausses nouvelles et la manipulation des réseaux sociaux. Il semblerait qu'elle soit à l'origine du vote du Brexit en Europe et aurait influencé de nombreuses élections en Afrique !
Ce qui a choqué aux Etats Unis : Facebook a vendu leurs informations aux Russes ! Pour eux, c'est un acte d'antipatriotisme. Depuis, Facebook ne progresse plus aux Etats unis, les gens se sont détournés vers d'autres réseaux sociaux ! Ce qui a choqué en France : on peut se servir de nos données contre nous, contre notre société et contre la démocratie ! La protection des données personnelles est devenue une préoccupation majeure, surtout depuis l'adoption du Règlement général sur la protection des données (RGPD) en Europe et d'autres lois similaires dans d'autres régions du monde. Ces réglementations imposent des règles strictes sur la collecte, le stockage, le traitement et la transmission des données personnelles, ainsi que sur le consentement des utilisateurs. Toutefois, la plupart des gens ne font pas vraiment attention à ce qu'implique le traçage et le suivi de leurs données personnelles.

La généralisation de l'IA
L'intelligence artificielle (IA) a émergé dans les années 1950 avec pour objectif de simuler l'intelligence humaine. Au fil du temps, elle a connu des avancées majeures, notamment dans le domaine de l'apprentissage automatique et du traitement du langage naturel. le développement des IA offre aux entreprises de nombreuses opportunités d'améliorer leur efficacité opérationnelle, d'innover, de mieux comprendre leurs clients et de rester compétitives sur le marché. C'est pourquoi tant d'entreprises investissent dans cette technologie et cherchent à l'intégrer dans leurs activités. Avec l'essor de l'IA, le Web a connu une révolution sans précédent. Les algorithmes d'IA permettent une personnalisation accrue des contenus, des recommandations plus pertinentes et des expériences utilisateur plus adaptées.

Les moteurs de recherche utilisent l'IA pour améliorer les résultats et comprendre les intentions des utilisateurs. Les chatbots et les assistants virtuels alimentés par l'IA offrent un support client instantané et efficace. L'IA contribue également à détecter les comportements frauduleux, à améliorer la sécurité en ligne et à automatiser les tâches répétitives. Elle facilite la traduction automatique, la génération de contenu et la création de sites web dynamiques. En somme, l'IA révolutionne le Web en le rendant plus intelligent, interactif, sécurisé et accessible, ouvrant ainsi la voie à de nouvelles opportunités et expériences pour les utilisateurs.
Les IA permettent de fabriquer du texte, des images et du son !, Ainsi chat GPT et Midjourney génèrent énormément de revenus ! Des investissements très importants sont réalisés et ces outils progressent à pas de géant ! Ainsi des internautes se sont amusés à tester les évolution des IA en leur demandant le même prompt à chaque fois et en enregistrant systématiquement les réponses des robots pour mesurer les progrès. En quelques mois, les progrès sont tout simplement incroyables !
Dessine pikachu

Dessine une licorne

Dessine des hommes préhistoriques prennent un selfie car ils viennent de découvrir le feu !

Dessine un jeune homme qui pose avec un lion

Dessine des chevaliers en armurent qui mènent l'attaque contre un hélicoptère !

Dessine un paysage multicolore au coucher du soleil

Les images deviennent de plus en plus crédibles et il devient de plus en plus difficile de les identifier comme des images créent par des ordinateurs, sans lien avec la réalité. C'est pourquoi, le 2 février 20254, l'IA Européean act est signé afin de réguler les intelligence artificielles, notemment l'obligation pour les auteur de laisser des traces imperceptibles de leur origine artificielle afin de les identifier plus facilement et contrer les fakes news !